The following document is intended as the general trip report for me at the 2023 SREcon Conference held in person in Santa Clara CA from March 21–23, 2023. It is going to a variety of audiences, so feel free to skip the parts that don't concern or interest you.
Today was a travel day. I was up by 3am so I emptied the dishwasher, finished packing up, set the thermostat to heat to 64, and headed out to Metro. At 4am traffic was light and moving well, and I got a decent parking spot in the Big Blue Deck (level 3 zone E2), a short walk over to the terminal. Escalator up, over, escalator down, over, a short wait for the interterminal bus, and I was at the McNamara terminal. Printed my baggage tags and dropped them off with the airline representative, had a brief wait to get through security (while I was in line they opened a desk for a second agent and opened a third scanner), and my bags wound up going through twice (and I have no idea why). Wandered over to the tram, got to my gate (A27), and caught up on most of my magazine backlog. Eventually we boarded.
The first flight was a little bumpy at times but not bad. What was bad, or at least annoying, was that the in-flight entertainment (IFE) system was down (although the pilot for free WiFi was fine). Despite two or three "hard resets" it wouldn't load for most people. The flight attendant confirmed our email addresses and had a 2,000 mile consolation bonus applied to our accounts, which was a nice gesture. We landed early at Salt Lake City — and amusingly enough, as soon as the wheels hit the tarmac my IFE screen started working. Anyhow, we had a brief wait for our gate to become available and still arrived early. My second flight would be boarding from the next gate over so I recharged my phone until it was time to board The second flight was bumpier thanks to weather over the mountains, and was annoying in that the IFE didn't work and the "free Wifi" was limited to iMessage, Facebook Messenger, and WhatsApp and not any of the apps I'd be using. We arrived early at San Jose, too.
Baggage claim was confusing... at least on the part of the airline. The signs said our bags would be at A4 but the loudspeaker announcement stressed they'd be at A3. Then at A4. Then at A3. They eventually came out on A3. My bag was tagged with the "priority" label but still came out near the middle to end of the bags (it's supposed to have been in the first batch).
Caught a Lyft (brief delay while waiting for someone) to the hotel, had no wait at checkin, and my room was ready. I went upstairs, unpacked, showered off the ick of travel, got dressed (yay, forethought in bringing an "extra" set of clothes for it), and headed down to people-watch in the lobby. I did get to catch up with a couple of people (P.'s company got bought by F5! B. moved to a 4-acre property outside Sacremento!) before the badge pickup opened at 5pm. Printed my badge, affixed my pronouns sticker, chatted with more folks (including a USENIX board member or two), and eventually did a (way overpriced) grab-n-go carne asada burrito from the lobby market.
By the time I finished the burrito it was pushing 7pm local time, or 10pm biological time, and I'd been up for 19 hours at this point. I headed back to the room, popped my regular evening meds (with an added muscle relaxant), and crashed.
I woke up after about 9.5 hours of sleep. Did a little bit of day-job work before taking my daily COVID test (negative). I then showered, packed up the laptop, and headed down to the lobby for breakfast (eggs benedict, sausage gravy, fruit, and pastries) where I chatted with someone from Crowdstrike who I'd see speak in the last session of the day and a couple of people from Bloomberg) and then to the attached convention center for opening remarks.
Opening remarks
[No slides | No direct video link]
The conference proper began with a themed introduction from co-chair Sarah (co-chair Mohit could not be here). We all come in for different reasons and with different perspectives. What do you need: Knowledge, networking, vendor demos, hallway conversations with friends, or a combination? We hope the programming gives something for everyone. We're caught between the privilege of working in technology, but it's often challenging and thankless. We're excited you're here and hope you can make it what you need it to be. "We have an agenda. We don't have an agenda for you."
They reviewed the code of conduct; we want to be a safe environment for everyone. They encouraged people to wear masks where appropriate (some are available at the registration desk). The Slack channels are where changes are announced and the talks' Q&A will take place (#23amer- is the prefix). Thanks to the sponsors (the showcase is open all three days; please visit).
Q&A will be different this year: We'll be using the day-and-track channel with :question: as the question prefix, and moderators will ask them.
We have over 650 people in attendance (though unlike last year the conference did not sell out). In a later discussion, someone asked whether this was bigger or smaller than LISA. That brought up the question of "when," as LISA had typically around 1,000–1,200 people (2004–2015, with a dip to 860 in 2009/Baltimore and a spike to 1,200 in 2011/Boston), we dropped to 700–850 (2016–2019) and only had about 400 people in 2021 (virtual only).
The schedule has shifted as speakers and sessions had to be moved around.
Plenary: The Endgame of SRE
[Direct slides link | Direct video link]
Despite all our automation and tools, we still have incidents... often caused by something in the sociotechnical realm. We used an RPG metaphor and demo to talk about retrospectives. When investigating incidents there's the leadership, the SREs, and other teams that have various degrees of experience and expectations and views. Engineers should talk to the Sales folks to find out what the customers are actually saying.
The example included a completely toxic team.
The whole story: A normal feature developer noticed some db tables were inconsistently named so their push cleaned it up, not understanding that others outside her team would rely on those names. The migration failed but wasn't actually rolled back. That caused the toxic team's code to break, and customers using the renamed tables started seeing failures... and burned through the entire error budget. We explicitly haven't used the words "root cause" because doing that would lead people to blame the deploy that failed and to move on. It would ignore the contributing factors. Some things:
- The team doing the deployment is oversaturated.
- What failed, what checks went into effect to prevent it from recurring?
- Their manager will push back harder to leadership because of oversaturation.
- Customer-facing metrics with the error budget caught the problem earlier.
- A team was surprised by an unknown unknown.
- Adaptive capacity was built in and work happened... and that's resilience.
Resilience helps people grow (and is different from robustness).
Telling the story through a game engine (RPGMaker on Steam) was a lot more interesting than PowerPoint. She used Itch for the town.
Q: What about adaptive capacity in regulated industries?
A: Even if you don't have a run book you still have to fix the problems. They need to understand what the regulations do and don't allow, to help folks find the ability or develop deeper tools to be able to do it within regulation.
Q: Is the interview scripted?
A: Initially yes, but going off-script is encouraged, to identify surprises. Once you're talking with someone and they feel safe with you they'll share more information (including possibly-relevant emotional state).
Q: How do you get these disparate teams to talk to each other?
A: It's a more leadership hybrid role. As a senior product engineer she's got relationships with the leaderships beyond her own team. Building those relationships encourages connections and getting them to talk to each other.
Q: What about measuring adaptive capacity or maturity?
A: It's virtually impossible; it's like education in that it exists in a person and can be tested via standards... which are themselves problematic and measure more socioeconomics than knowledge. Adaptive capacity is when people feel safe and leads to surprising results and innovations. "Don't measure" is the reccommendation. If you have to measure something, measure how many incidents get retrospectives?
Q: What is a good way to approach trying to provide an answer to someone who wants to know exactly why something happened, and there is no really clear answer? Providing the contributing causes?
A: Say "No" to providing a root cause but mention the contributing factors.
Plenary: SRE's Critical Role in the COVID-19 Pandemic Response in Government
[Direct slides link | Direct video link]
USDS is part of the executive branch and are civilian employees, not contractors. They talked about three projects and how SRE was an important part of all of them.
First, we need to be aware that operating in government has more regulatory constraints leading to more roadblocks, red tape, and bureaucracy than otherwise. For public health issues like COVID-19 there's the federal, state, territory, county, and city level governments all overlapping. The objective functions in business tend to be "make revenue" or "make profit," which doesn't apply to the government; the objective functions of the government vary depending on the project. For USDS, theirs is "What will do the greatest good for the greatest number of people in the greatest need?" In government there's no real ability to test on a subset of people; it's all or nothing, and needs to be used regardless of age, tech savvy, disability. That means having to operate in different ways.
Testing and reporting data pipelines
The problem here was that COVID testing was happening without a doctor and not necessarily in a formal medical test site. Those places often don't have an electronic health record so they have a lot of paper... which gets shipped to the Department of Public Health. That means having to go through manual entry (lots of people, potential for lots of errors, and greatly slows the test-to-EHR timeline)
The solution was to build a simple website, SimpleReport, so places without EHR could submit the data. That would go to the new ReportSteam product that could deliver that to multiple (federal and state, etc.) public health departments. The website was built with the goal of increasing the efficiency of the people doing the work with minimal training.
ReportSteam takes data from labs, hospitals, and so on, then routes it in the appropriate formats to the states and feds.
So did they do this fast, especially from scratch and under a regulatory burden? They used a "lean startup" methodology (do only what you need to build the minimum-viable projects) and they built two complementary projects to allow for independence, smaller teams, and smaller meetings. They could deliver a first test result in six weeks.
This introduced new DevOps and SRE practices (logging, auditoring, monitoring, infrastructure as code, CI/CD), technology, and values (including blameless retrospectives and continuous improvement) to the CDC.
They scaled for the omicron spike without problems. Over 33M test results were delivered (no longer on paper), signed up over 15,000 different facilities (nursing and long-term care, schools, parking lots, and jails) using the product, and was used for mpox as well.
Helping people find vaccine appointments
SREs' focus on service delivery can unify diverse stakeholders.
The architecture is pretty straightforward — frontend, cache, backend dab, with appointment API and provide dashboard. The complexity is that each of those components was owned by a different government agency or (sub)contractor... and USDS is not represented in that org chart.
The appointment availability API was to bring together providers and governments. They tried to design it by committee based on limitations of partners' technologies. Based on the urgency of the problem and the high visibility of the project they were able to move past the roadblocks. They planned to launch when the president announced the URL on TV during, say, the State of the Union: High scrutiny, high load, and high probability.
Challenge: No such thing as a soft launch for .gov websites. They soft-launched at vaccinefinder.org instead. That let them defer section 508 (ADA) compliance. Lower bar to launch.
They created a service-optimized prioritization of outstanding work, prepared for load (moved from address to ZIP code search), and did a teamwide incident response simulation (which was very helpful in learning how the different organization works). They also designed an API (out of committee) and brought it to the committee for comment and changes.
Result: They had 110.1M sessions, 2 weeks shorter wait for the appointment, and was all developed over only two months.
Providing access to at-home tests
Connecting technology and policy... but "policy" here is more like "business rules."
Distributing free tests to the public was determined to be the best course of action. They had 2 months from inception to launch, started with 500M tests (that became 1B tests), and 150.4M addresses in the US. USPS delivered 6M packages per day.The requirements were straightforward but there were many ways to implement them ("distribute tests to all people in the US for free"). Technology-informed product decisions can have a huge impact on launch velocity. This lets them have a simple 2-tier system: A static landing page and with a button to the order site, and that site that accepted name, address, email if you want updates, and a Submit button. No option for one versus five tests; everyone would get four.
They were concerned about the load, especially given a large public announcement. They implemented a super-easy launch throttle: The "Order tests" button was limited to 1%, then 10%, then 50% of the public. They could bleed the load on and monitor as things scaled.
⅓ of US households ordered in the first 24 hours, and ½ in the first 72. The system handled the load spikes. They delivered 749.7M in 185M packages... and it was trivially easy for the consumer.
SRE was a core part of USDS' pandemic response. Everything required digital components. This was a core part of the pandemic response, and having SREs part of the projects made a huge impact on getting the projects done at all. Note that this means we all have the core competencies to make a huge difference, which is often easy to overlook. Our best practices can absolutely make a difference.
We're Still Down: A Metastable Failure Tale
[Direct slides link | Direct video link]
After the morning break I went to track one. It started with the invited talk "We're Still Down: A Metastable Failure Tale" from Kyle Lexmond at Meta.
What's a metastable failure? There's a trigger that causes a system to enter a failed state that remains once the trigger is removed, when in the bad state it's unusable, and it's not able to self-recover. This is similar to cascading failure (where self-recovery is possible).
Europe had scheduled a simulated DRP test. Kyle was on the East Coast, the oncall was on the west coast, and alerts were flooding the CDN team channel. An entire group of systems disappeared. It was as if there was a power outage... but they had power but weren't pingable. Rebooted anyway, canceled the DRP testing, and the machines had come back... but then stopped responding to ping after a while.
The CDN architecture has some peculiarities. They have some unique points: They store at least two copies of the photos and videos you upload (they're copied to a second region). How does the algorithm know which region to pull the uploaded content from? They use routing rings so there's a unified global view... but since the content is in only two regions the ring is pretty simple. When a region failure is detected traffic is sent to the other region. The decision is made by the local point of presence (POP): If the media isn't cached the POP pulls it from the region (which has a web server that fetches the image from storage, transcodes it if needed, and sends it back through the web server).
In this incident, more than one region was impacted which could indicate a cascading failure. They were seeing waves of requests going from region to region, causing each to become unhealthy in term, lather rinse repeat.
This was both a cascading and metastable failure.
They tried physical recovery first. Some machines were crashing when they ran out of memory. Next they tried load shedding; Tightening the rate limits, disabling background content fetch, and adding more web servers to the pool.
They were still down. They were almost to the point of turning off the CDN. Instead, they turned off the health checks. Machines that were unhealthy became healthy, machines that were rebooted stayed up. This spread the load widely enough to prevent individual hosts from getting overloaded. They needed to reduce the average request per machine (regardless of whether the machine was actually up). By not having a thundering herd of traffic it broke the sustaining effect of the metastable failure.
"Many load-balancing systems use a health check to send requests only to healthy instances, thouh you might need to turn that behavior off during an incident to avoid focusing all the load on brand-new instances as they are brought up. " — Laura Nolan
So what really happened? The transcriber was overloaded and sent requests across regions. By default it compresses traffic between regions. But this content isn't compressible. The CPU couldn't send bytes out (to the transcoder or user) fast enough to process data from storage and so they crashed.
What hindered and what helped?
- Hindered:
- Delayed realization of the incident scale.
- Having two distinct failure modes (crash vs. going unhealthy) was confusing.
- Health checks were affected by load shedding, causing traffic oscillations both between regions and within a region.
- Helped:
- Failed system was isolated from other services (CDN read path).
- POPs continued to serve stale content.
What changed, design wise, to prevent these oscillations?
- Spread traffic across all machines (not just healthy ones) if there's fewer resources than the threshold.
- Prevent the health checks from being subject to load shedding in the web server.
- CDN design now rebalances routing weights to reduce magnitude of traffic shifts under RD, and periodic automated (re)calculation of weights based on demand and capacity.
- New automation to support tier isolation (internal vs external)
- Stronger container-level isolation and resource limits
- Accelerated effort to add auto scaling to the transcoder and web servers.
Q: Do you use a commercial CDN like Akami or a custom?
A: Custom.
Q: How much sleep did you lose?
A: Only the on-call person lost sleep. and only woke up an hour before normal.
Q: Can you expand more on a decision for pops to remove themselves as opposed to quorum style health checks? Sounds very similar to recent Meta DNS/bgp outage.
A: We want the POPs to make their own decision in case the network layer fails (despite redundant paths).
Q: Impressive list of remediations! Have you seen any failures since then that involved any of these remediations going awry or creating unexpected behaviors?
A: Probably? This incident happened a while back, the changes were a couple of years ago. He's since moved to Storage and hasn't seen as large an incident.
Q: How big was your CDN SRE team (when this happened)?
A: Four people, but it's grown significantly since then.
Q: Related to load testing, at what scale or frequency do you load test?
A: They test the entire stack. They've talked about them in the past but the information may be proprietary. At least 3 months.
Q: Is this synthetic load testing or regional failure (disaster recovery)?
A: Both.
Q: Do you adjust the load limits often based on new observed data? How often does the team visit this to update scaling limits?
A: The team doesn't; it's all automated now.
Q: What if the cost of the solution is orders of magnitude larger than the cost of the failure?
A: That's a VP-level decision. They delayed the roadmap for a quarter to fix things. They were lucky to have a VP/director/manager for doing so.
Q: How long were the health checks turned/left off, and was turning it off manual or automatic afterwards?
A: Off for about 90 minutes. A human has to pull the trigger to disable the health checks (it's in the run book).
Q: Do you think that these sort of metastable failures occur only in high-load situations, or are there situations where a sustaining failure is not load related?
A: No. The trigger is often, but does not have to be, load related. Load is just the most common.
Q: Would it be a good idea to gradually add noise (randomization) to the health checks during an ongoing incident as a general strategy to deal with cascading/metastable failures?
A: We didn't think of that. We'll update the thread later.
Q: What sort of skill sets are typically used on your day to day?
A: Specific-to-CDN, mostly Linux and system level how things work, but less so networking. Lower-level Linux stuff (kernel, syscall, etc.). Now he's in Storage which is a lot more Python and cross-team political discussions.
Watering the Roots of Resilience: Learning from Failure with Decision Trees
[Direct slides link | Direct video link]
Next up was Kelly Shortridge from Fastly about resilience. Humans are the mechanism for adaptation in a software system. How can SREs align their mental model to sustain resilience.
Adaptation in complex systems. They present a large variety of possible states making prediction impossible. Getting from point A to point B is more like a cat zoomies as opposed to how a crow flies. The reality is failure is inevitable; it's a natural part of complex systems as they operate. What we see is that successful complex systems are adaptive, they evolve and change in response to change in their environment. (See adaptive capacity from earlier today.) Resilience is the ability to prepare and plan for, absorb, recover from, and more successfully adapt to adverse conditions.
There are five common ingredients for resilience:
- Define the system's critical functions.
- Define the system's safe boundaries
- Observe system interactions across spacetime.
- Feedback loops and (blameless) learning culture.
- Flexibility and willingness to change, sustained over time.
So what's adaptation for computer systems? The ability to respond to unexpected input, flow, volume, etc. But that ignores the human aspect; humans and machines continually influence each other. Humans jump in when machine processes fail noticeably. Software has very limited ability to adapt on its own. For example, the log4Shell attack was mitigated by the socio part of the sociotechnical system.
Mental models are dynamic, incomplete, and inconsistent. Surprise is the revelation that a given phenomenon of the environment was, until this moment, misinterpreted. We must prepare to be surprised.
Chaos experiments give for resilience testing. Reality is messy. (Don't start by testing in production, but the environment needs to be "lifelike.") We want to assess the nature of the system and its interconnections.
Chaos experiments Tyical tests Support resilience Support robustness Sociotechnical (includes humans as part of the system) Technical (excludes humans as part of the system) System-focused Component-focused Capable of being run in production Must run in dev or staging Random or pseudo-random Scripted Adverse scenarios Boolean requirements Observe and learn from failures Detect and prevent failures N-order effects Direct effects Case study: A manufacturing company had a physical parts database for its East and West coasts' sites. Data is replicated. Want to be able to operate on data that is not too stale. How do the systems behave when replication is severed or when it gets too far behind? Does it know it's using stale data? Is there alerting? What if it's using parts that don't really exist? Potential experiment: Sever the replication connection and see if things recover. If the test failed that may lead to design challenges. They do that and then rerun the test. Replication was faster (yay) but no alerts were fired (boo). Reevaluate, redesign, lather rinse repeat. (These can include security issues too since they can become reliability problems. Attackers love to take advantage of interactions between components to compromise a system.)
Security Chaos Engineering (SCE) is a socio-technical transformation that enables the organizational ability to gracefully respond to failure and adapt to evolving conditions.
SCE aligns our mental models with reality and improves our systems resilience to attack. In practice, start with a hypothesis: Our assumptions (mental models) of reality. What assumptions are we making that are "always" true... that may not be.
We walked through a decision tree about "missing logs." What are the possible causes and mitigations? (Decision trees are a powerful tool we should probably use more often.)
Decision trees should cover all issues, including already solved ones, because context changes over time. They capture system architecture flows, as well as any gaps where we're unprepared. They're great for blameless retrospectives; the tree was wrong, not a person. Starting down easier paths may be easier for people new to them.
For more information, including a walk-through of actual decision trees, refer to the slide deck.
Scaling Terraform at ThousandEyes
[Direct slides link | Direct video link]
After lunch (soup, salad, hot and cold sandwiches, and sides) I went to the "Scaling Terraform at ThousandEyes" talk from Ricard Bejarano at ThousandEyes. We're familiar with the benefits of infrastructure as code, and while Terraform is arguably the best tool it doesn't scale.
At some point, once you have enough resources, any change will cause a refresh and redeploy and flood the system with API calls. You can disable that but there are risks of deploying the wrong or outdated things. Yes, you can break them from One Big Deployment into several smaller ones (prod vs staging, region-based, workload-based, and so on). But that can lead to bigger problems: It opens the door to drift potential. The different deployment files should be the same but they're different files and can contain different pictures of what the infrastructure looks like. Fixing drift in Terraform is horrible: Either reimport and roll things back but since resources can depend on each other this is exponentially hard. Alternatively, redeploy and fix things. There are also problems with boilerplates containing a lot of duplicate non-functional code.
They looked at existing solutions. Terragrunt, which can fan out Terraform deployments to as many targets as you want. But it's got a learning curve, doesn't solve the boilerplate problem, and they already had 5,000+ Terraform files. Since they offer Terraform as a service to their organization they didn't want to add another tool and another learning curve.
They built their own tool, called Stacks for Terraform. It adds a layer of abstraction in front of it to define a code base before fanning things out the the rest of terraform.
vpc/ +-- base/ | +-- vpc.tf | +-- subnets.tf +-- layers/ | +-- production/ | +-- layer.tfvars | +-- staging/ | +-- layer.tfvars | +-- vpn.tf +-- stack.tfvarsThis lets them keep drift under control and get rid of boilerplate (since Stacks does the injection).
The developer experience is better; repos only contain resources because state and providers are all managed in Stacks. It allows the admin to enforce a common set of behaviors so the developers don't need to worry about it.
Extra features in Stacks for Terraform include cascading variable scopes; auto-injected state backend, providers, and so on; auto-declaring variables; secrets injection; jinja2 templating (so Stacks interpolates variables before Terraform can see them, because Terraform can't use variables for everything; and more.
Reference architecture: GitHub (monorepo) → Atlantis (automates Terraform from PR and posts plan output) → Stacks → Terraform.
Summary:
- Even with all its flaws Terraform is still great.
- Modules only get you so far; we need a better way to scale.
- Code preprocessing works.
- Stacks for Terraform.
It's Open Source as of this past Friday (hooray!).
Epic Incidents of History: The 1979 NORAD Nuclear Near Miss
[Direct slides link | Direct video link]
After the Terraform talk I switch back to track one for Nick Travaglini's "Epic Incidents of History: The 1979 NORAD Nuclear Near Miss" talk. Basically on 1979-11-08, a NORAD officer put simulation data into an ICBM early-warning detection system and that almost led to "retaliation." See also the paper "Multiple Systemic Contributors versus Root Cause: Learning from a NASA Near Miss" (Walker, Woods, and Rayo).
Distant Developments
In WWII computers were humans (and then later machines), used to coordinate anti-aircraft ballistic missiles. Very much then-superior analog technology. Vannevar Bush and the institutionalization of Big Science (and Engineering) led to the "Iron Triangle," military-industrial-academic apparatus. Those forces set the stage for developing digital computers for military command-and-control purposes.
The Office of Naval Research initially funded Jay Forester's Project Whirlwind, a general-purpose flight simulator, and measuring versus counting for increased speed and accuracy. They really wanted a general-purpose computer and weren't getting results they wanted so they started cutting his funding. The Air Force stepped in to save the project, advocating radar early warning over point-defense. But triangulating on incoming planes would require many radar stations in various locations.
It became SAGE, the first-ever large-scale computerized command, control, and communications system. It was obsolete before it was completed. It produced core memory, visual displays, analog/digital conversion methods, parallel and multiprocessing, and networking.
Other devices and advances are happening, such as ICBMs, both land- and submarine-launched. Along with this the Space Race is happening... which served as cover for Cold War maneuvering. RAND (the Air Force think tank) was developing game theory to strategize nuclear war, and what the likely responses would be, and what casualties would be, and so on.
As computers became more networked and tightly-coupled, it became more and more difficult to determine where an error might have occurred and less and less easy to interpret the signals. The military wound up standardizing on one system (WWMCCS).
NORAD's 427M system had 3 primary components:
- CSS
- NCS
- SCC
Purchasing was horribly disjointed. They were mandated to use the mandated Honeywell systems as WWMCCS.
As of mid- to late-1970s this was still under replacement (since 1966). NORAD wanted a fourth component for testing their corner cases, but that was denied due to costs. They had to test in production.
Proximal events
Officers began preparing for a test operation later in the day. They attempted to input a data reel tagged as test data through a test device. The Honeywell computers were in Hot/Shadow mode so both of their processors matched and used the same data. (This was a regular procedure since 1978.) However, this time the MG/R and the CSS failed to connect properly.
The officers tried another tape (the "NJ Scenario") that wasn't tagged as test data. They'd used it before to override test-tagged data on the wire. The MG/R and CSS behaved ambiguously but the officers believed nothing was transmitted.
Meanwhile, a circuit transmitted satellite data blipped and the MG/R went to a different backup connection. The last signal from Buckley had been 001 and the NJ scenario began with 002, implying the satellites had picked something up. The CSS transmitted a signal indicating that 1,400 nuclear-tipped missiles were incoming.
A threat assessment conference call began within about a minute. Counter-offensive plans were ordered to prepare to launch but some actually launched due to patchy phone connections. Responders cross-checked against alternative data sources, like PAVE PAWS, which didn't detect the launches. Incongruities between the time of day and the MG/R data undercut its credibility. NORAD decided it was a false alarm (within about 6 minutes). The presidential evac plane took off without Pres. Carter. The DOD blamed "operator error" and NORAD built a dev/test facility and made some other changes.
Review and takeaways
"Blunt-Distant factors include pressures created by the blunt end and the priorities that are intentionally or unintentionally communicated through those pressures. Sharp-distal factors include adaptations formed to react to priorities communicated by blunt-distal pressures. These adaptations or beliefs have been used successfully in previous work. Blunt-proximal factors influence sharp-end behavior during the accident, and sharp-proximal factors are sharp end behaviors during the accident."
Where did the production pressure come from? The Truman Doctrine of "containment" to fight communism. It's a zero-sum us-vs-them US+allies-against-communists. Truman scared the hell out of people, pulling on religious iconography and treating it as an apocalyptic event. Zero-sum is a fallacy.
It's argued that the US military has this "closed world" mentality and didn't learn anything from this, beyond some short-term remediation efforts. They want objective certainty of the world.
If we think of our sociotechnical systems as complex and emergent, we need to ask critical questions like the operators did: Does this conform with other data sources (digital, technical, personal experience)? They made some noise ("An exchange of letters on the role of noise in collective intelligence"). Being an SRE means asking questions, thinking critically, and not taking things at face values.
Incident Commanders to Incident Analysts: How We Got Here
[Direct slides link | Direct video link]
After the afternoon break (dried fruit, nuts, pita chips, hummus, kale chips, and black bean dip) I stayed in track one and attended Vanessa Huerta Granda's and Emily Ruppe's talk, "Incident Commanders to Incident Analysts: How We Got Here," about the difference between the two titles.
Incidents aren't really distinct events but more as part of a lifecycle. System is normal, system fails (incident begins), incident resolution, post-incident activities = learning, applied to change the system, leading to a new system with load, and back to the start. The "learning" part is where we come in.
Investing in learning lets us turn incidents into opportunities. Systems break; we need to learn from that, invest in learning opportunities, and improve moving forwards.
Many organizations don't have dedicated incident commanders or incident analysts. Vanessa focused on incidents as a lifecycle and has been incident commander and led retrospectives, and scaled the process. Emily came into incidents through support, back when monitoring and alerting were new, and is on a spiral staircase (but isn't sure whether it's going up or down), and has been a dedicated incident commander who has scaled up a team of other incident commanders.
To be an effective incident commander, you don't command. You coordinate, think, listen, track the moving pieces and time, facilitate communications... You're conducting the orchestra of those doing the work. It requires some level of hyperawareness, to step back and see the working pieces of incident response as their own systems. An incident commander is troubleshooting the microcosm of that specific incident. Better terms might be Manager, Facilitator, or Conductor.
You'll be reviewing a lot of data, asking people to share their experiences and their point of view, building narratives and timelines, and sharing them with others. What are things that stick out? Caused confusion? Caused decision spirals? You want to surface insights about the organization. It requires sensitivity to their experience and context.
It can go wrong, though. The incident commander shouldn't do it all and probably shouldn't lead the analysis. We need to train people to troubleshoot, but analysis, interviewing, and so on. Having someone involved be the analyst can lead to biases in others' experiences. You need the right tools and the time to do it right.
One team can't do it all. It might be a good place to start, though. Maybe start with all the P0s. You need to include other points of view from the other teams... even if those teams are busy. Prioritizing the learning reviews and retrospectives is essential for sustainability of the program.
It's not easy, even with templates. Focus on the narrative story. Humans pass on information through stories. (See the "Howie" guide.)
Bring analysis skills into the response process: Be curious but not judgmental. You're not looking for action items or RCAs, and you may need to pivot from what you thought would be heavily discussed to other things.
Teams need to trust each other but don't necessarily have to like each other. Recognize that no thought or discussion at an incident review exists in a vacuum. We're all whole, complete, human people who may have other things happening. As incident commanders and incident analysts specifically you need to help people get through the incident. Remind them that they are still people and have permission to take care of themselves.
Q: In terms of "having people be full time" for command and/or analysis, what guideline would you suggest in "sizing" the role?
A: It's difficult to get a headcount for incident analysis. There's often a lot of carry-over with SRE. Start with one engineer doing a review every couple of weeks, or one doing several a week, depending on how thorough the review needs to be and how often incidents are occurring. After doing some analysis you'll see where the gaps are and will let you develop goals and guidelines.
Q: How do you gauge success as you're rolling out these practices?
A: You can't really measure success beyond not experiencing the same incidents over and over again.
Q: As an incident commander, did you notice a difference in incident resolution effectiveness whether you had worked with a completely unknown team vs a team you have more context about and worked before?
A: The experiences differ, and the amount of work you're putting in to tread carefully respectfully while still making progress will differ. Having a preexisting positive relationship can help. It's okay to have someone more familiar with a given relevant team be the commander.
Q: Does incident analysis responsibilities expand to automate or improve run books, or self healing scripts?
A: Incident analysis runs beyond running the retrospective, especially comparing incidents and determining trends across the organization. That can be making recommendations but not necessarily making the actual changes. The scale beyond that depends on the demand of the organization.
Q: What is your recommended on call duration and frequency that optimizes to reduce burnout but allows you to keep up to date?
A: Ask what the purpose of the review is. Build in recovery time especially if there's been a long incident.
Q: What would you say the top skill sets/abilities are for finding internal humans to fill these roles?
A: Curiosity and courage; don't be afraid to ask questions... even in a high-stress situation where everyone in the room may know more than you do. Not having an ego; recognizing you're part of a team, not the hero swooping in to save the day.
Q: Have you ever done a retro for the job of the incident commander separate from the retro itself?
A: Yes, absolutely. Take time, either in the actual review meeting or in another one, to surface that process. An incident commander team needs to share each other's skills and learn from each other. Also, the process you have today is unlikely to be the process in a year. Having weekly or quarterly reviews about how you're handling the incidents is a good idea.
Q: What tools do you need?
A: For incident analysis, some kind of collaboration tool — even Google Docs. Access to the information and a curious mind are essential. The "Howie" guide may be handy.
Q: What are some other good resources for engineers new to doing incident commander or incident analyst?
A: We'll link to some resources on Slack (and have a cheat sheet for the Howie Guide at their booth tomorrow). Also, you don't need to start with a fully-developed formal process. Perfection does not exist. Start simple.
Q: Any recommendations about oncall duration or frequency?
A: "It depends." What's your company culture about responding to being on-call? Is on-call something that folks dedicate themselves to for their period? How frequently are you seeing alerts? How frequently are incidents happening? What's right for one team may not be right for another. You'll need to adjust and pivot. Review how on-call has been going.
Handover Communications in Software Operations: Findings from the Field
[Direct slides link | Direct video link]
My last talk of the day was "Handover Communications in Software Operations: Findings from the Field" from Chad Todd at Crowdstrike (who, incidentally, I'd met over breakfast). He presented collected research from interviews, showcased the attributes that contribute to an engineer's increased or decreased confidence after a handover communication in understanding the current state of the system.
The passing of information through handover communications is essential in many workplaces. Handovers are crucial in industries such as health care institutions, nuclear power and software operations. Handovers in software operations happen on a daily basis much like in health care.
Examples of handovers in software operations include verbal or digitally written. They can occur during shift changes or on-call within a network operations center or customer support center. These handovers can occur during both high-stake and low-stake scenarios. Ultimately, confidence and understanding of the information is of the utmost importance.
Some guidance:
- Have a formal template... but don't enforce it where it's not relevant. Some sections may be blank or missing. Some information may be out of date. Having some predefined sections for guidance is helpful, but free-texting within that is useful.
- Limited processes and requirements.
Need to close the loop (acknowledge the handover). The outgoing engineer should be available for a few minutes after the handover in case there's necessary but missing context.
Now that we have the common themes, how can we put it together?
- Avoid inconsistency among the departments of what information is included.
- Be available after the handover to allow for questions and context.
- While preparing, don't oversubscribe someone; give them enough time to prepare.
- Formal templates can lack vital information, so allow for flexibility there.
- Allow for further exploration for information right after the handover.
- Verbal handovers need to support the digitally written handovers. Do you do one or both (and if so, which first)?
- Detailed handovers are of the utmost importance.
- Creating an embedded workflow or process for the handover can help reduce context switching.
- Guidance about what information to supply for each handover needs to be consistent across departments.
- Acknowledgement of the handover is required.
Q: What is a good strategy for encouraging or motivating on-call folks to attend a handover in the first place, who might feel it is "another meeting" they don't want to be interrupted by?
A: It shouldn't be seen as a meeting but more as part of your "normal" job. Motivation is helping your colleagues... and not getting called back in later.
Q: Given these issues, written vs verbal, verbose vs brief, pros/cons of templates, how would you recommend a team with no prior experience with it, start doing handoffs?
A: Look at the thesis which has a Slack workflow (with a Zoom or Teams call behind it). Starting there and building it out iteratively is a good starting point. Consider starting verbal and moving to digital next.
Q: Does doing handovers in a chat platform provide wider accessibility? Like for people who don't want to speak up in a call, or have a disability?
A: Slack provides the a11y and doesn't force people to participate verbally. Ideally verbal supports the digital.
Q: Did you look at the pros and cons of handover? That is, at what time you should perform the handover, and when it may be better to "hang on just a bit more." Outcome-related, but also from a human perspective?
A: His questions didn't follow that path; he focused more on the handover and confidence than on when they should be. You need to close the loop eventually.
Q: Did you do research on different levels of handovers? For example handover from executive to executive (or lead to lead, or incident commander handover)?
A: Handovers were observed (informally) just between engineers. There wasn't executive-to-executive modeling. He did six interviews (originally wanted 15 but between the transcription and other back-end encoding that was too many), so he did two teams of three.
Q: Do you think about handover communications strictly in terms of incidents? Or does it apply in other areas, like bug triage or customer feature requests, where information gets passed through multiple layers (with different contexts)? The research framework seems like it could be applied pretty flexibly.
A: All of it, yes. It's definitely extensible to other areas (consultancy handing over to the customer, feature requests from Sales to Engineering, shift changes in retail, and so on).
Q: There was a mention of integrated handover tools (to avoid context switching). Can you give an example or two?
A: If you use Slack, use a workflow in Slack. If you use Teams, use a workflow in Teams. Don't switch to yet another tool just because it's there.
Q: Are there any differences in how handovers work across different industries and/or cultures?
A: Yes. Healthcare has popularized this a lot. They do two things there: Can be done at the nurses' desk or walking room to room. Can be done via WhatsApp (but the UK WhatsApp outage meant having to move to paper). It varies by industry. With our technology we're more likely to be verbal and digitally-written, but others need physical paper.
Q: What are some questions you would ask in interviews to judge the effectiveness of handovers? How can I assess the current handover situation in a blame aware manner?
A: See the appendix of the thesis. It provides the full gamut of questions.
After the sessions there was a happy hour at the vendor showcase in the Grand Ballroom. They provided a Mexican spread (for taco Tuesday?) of carnitas or chicken nachos and churros. I met up there with some friends and strangers and a group of six of us adjourned to Truya Sushi in the hotel for dinner. Four of us split a couple of orders of sushi deluxe (eight nigiri and eight pieces of California roll), two orders of sea water eel (anago), and three rolls (dragon, Philadelphia, and rainbow), one of the others had a miso soup and another had a seaweed salad, but I didn't bother with those. Since four of the six of us were all from the same company (Stanza), they were kind enough to pick up the bill, too, which meant I might not go over my per diem this week.
After dinner I swung by the vendor spaces (and chose not to get more wine) and then swung by the LISA Retrospective BOF. Four of us — Brian (host), Garrett, Tom, and I chatted for a bit before I called it a night and headed up to bed (with added muscle relaxant beause my back and hips are unhappy with the conference facility chairs).
I woke up after about seven hours of poor sleep. Did a little bit of day-job work before taking my daily COVID test (negative again). I then showered, packed up the laptop, and headed down to the lobby for breakfast (scrambled eggs with cheese, breakfast potatoes, bacon, fruit, and pastries) and then to the attached convention center for day two.
The Best SREs Seem to Be the Ones without an SRE Title-And What We Can Do about It?
[Direct slides link | Direct video link]
In an industry where the SRE discipline has been growing (for a while now), with teams springing up everywhere, to do, well, SRE-but if Bob or Mary from that other SRE-like team are mostly the ones called for help to solve complex incidents, or other ambiguous production issues, what are the rest of the teams with the (official) title doing? Acting as a crutch? Baby sit legacy systems with a lot of toil? Doing low-value work no one else wants to do? Clearly, this is not the right direction we want for the profession or the industry. Kishore Jalleda's talk surfaced this seemingly universal problem, and discussed what brought us here, the potential risks of inaction, and offered practical solutions with actionable advice.
Example: Something on the east coast caused a global SEV-1 outage. The recovery happened within a few minutes, but caused a cascading failure with a distributed app. Failure symptoms pointed to the wrong teams causing multiple reassessments and delays, and insufficient alerting and observability compounded the problem. Seven teams were involved in mitigation (SRE, four different Engineering, Triage, and internal customers). The problem actually turned out to be the network (a fiber cut in a data center). How could it have been handled better?
One of the first questions was "Is the platform healthy?"
Contributing factors include:
- People don't understand the true spirit of SRE, leading to resource misallocation, inefficiencies, and wasted efforts.
- Individual contributor/leadership misalignments leading to anti patterns and wrong incentives.
- Tooling built by non-practitioners leads to low adoption, ROI, and efficacy.
How'd we get here? Ops and silos → DevOPS and PE → SRE as buzzwords (without understanding).
Here are four practical solutions:
- Platform competence — What are you responsible for and structure the teams accordingly. There are five areas:
- Capacity, cost, and risk management
- Incident management tooling and cadence
- Build and release
- Observability, monitoring, and alerting
- Disaster recovery, business continuity, and high availability
- More coding — Have coding goals for everyone... including leadership. (Not necessarily HR and Marketing, but at least Engineering up the chain to the VP/Director level.) Those goals will be different based on role, but everyone needs to code. Start with some official coding goals and KPIs.
- SRE Management 2.0 — Be aligned with management and corporate. Write code. Evangelize your team's projects, products, and tools. Continuous performance and people management using tools. Review your team's code. (And flatter orgs are better. A VP/director with two direct reports doesn't cut it any more.)
- Next-generation tooling — Attributes for next gen tooling:
- Observability and analysis of unstructured data
- Observability of your platform
- Opinionated domain cadence
- Human-centric design and human factors
- Asynchronous workflow orchestration
- NLTs and knowledge graphs
- NLP-based design
- Scalable multiplicative actions
- Collaborative interplay and synchronization
- Context modeling and situational awareness
- Asset/attribute correlation mining and intelligence
- Inclusive post-mortems or post-incident reviews
What Does "High Priority" Mean? The Secret to Happy Queues
[Direct slides link | Direct video link]
Like most web applications, you run important jobs in the background. And today, some of your urgent jobs are running late. Again. No matter how many changes you make to how you enqueue and run your jobs, the problem keeps happening. The good news is you're not alone. Most teams struggle with this problem, try more or less the same solutions, and have roughly the same result. In the end, it all boils down to one thing: keeping latency low. In this talk Daniel Magliola presented a latency-focused approach to managing your queues reliably, keeping your jobs flowing and your users happy.
Example: Jobs got stuck in queues due to increased load. How do you split them up and prioritize them (especially if the queuing system doesn't support that)? Throwing more workers at the problem isn't sufficient. Organizing by priority or importance is doomed to fail because the terms aren't always well-defined, and predicting interactions is hard. If the queues are purpose-based instead that helps... but doesn't scale. Teams need to act independently but you can't throw additional team- and purpose-based queues at the problems.
What problem are we really trying to solve? It's not necessarily jobs, priorities, threads, or queues. It boils down to "A job is running late[r than I expected]." That's no indication of the health of the queues, and it's not clear what queue a new job should go into. We should therefore assign jobs to queues based on latency: How long can it wait to run the job before it seems late?
Name them after the maximum latency, such as within_1_minute, within_10_minutes, within_1_hour, or within_1_day. Alert if the queue is falling behind. That sets clear expectations (or even a contract — including a time limit on how long the job can run). That also allows for metrics to monitor so you can notify when latency exceeds the maximum allowable by the queue name. What about prevention? Can we autoscale (e.g., if latency => 50% of the queue maximum, then add more servers)?
Queues and time limits:
- Jobs in the within_1_minute queue should run for no more than 6 seconds.
- Jobs in the within_10_minutes queue should run for no more than 1 minute.
- Jobs in the within_1_hour queue should run for no more than 6 minutes.
- Jobs in the within_1_day queue should run for no more than 2.4 hours.
About time limits:
- Detect trespassers. We need to know if a job is running too long.
- Enforce the rules. If a job is breaching the time limit it needs to be explicitly allowed to move it out.
- Respect the latency principle.
It may be necessary to stray from the latency-only naming. Some jobs may need special hardware or other specifics (within_1_hour_high_memory, within_1_minute_singleton, within_10_minutes_high_io, etc.).
Confessions of an SRE Manager
[Direct slides link | Direct video link]
After the morning break (mm, banana) I attended Andrew Hatch's "Confessions of an SRE Manager." He attempted to demystify and clarify for SRE individual contributors what SRE Managers care about, why they make the decisions and trade-offs they do, and, more importantly, how individual contributors can work better with SRE Managers to achieve their personal goals. SRE individual contributors can better understand the pressures and competing priorities that SRE Managers must work within, how to position themselves for career advancement and gain more insight into why specific work and decisions need to be made. He also showed what bad SRE Management looks like, how to recognize it, and how to avoid repeating it in a future management role.
Why give the talk? Managers who yell, who make their employees cry, who work people to death, who had the technical chops but not the emotional chops, and so on. He went into management to make a difference and try to be better for his people.
When you become a manager:
- You won't sleep well every night.
- There can be a lot of emotional labor.
- Humans are not perfectly rational creatures.
- Perfect and simple work processes do not really exist.
However:
- When things go well they're awesome.
- You can have a strong impact and be a force for good.
- You love working with lots of people and seeing their careers grow.
Management ≠ leadership.
He talked about what it is he does as a manager:
- Turn strategy into work.
- Manage a budget.
- Deal with vendors.
- Deal with legal.
- Deal with the entertainment budget.
- Deal with the people side, including emotional support.
- Letting someone go.
- Semiannual calibration sessions.
- Tactical and strategic processes.
- Writing code and shipping products.
- Keep reports and dashboards updated.
- Change when priorities do.
- Deal with ambitious engineers who just want to do their thing.
- Keep work visible.
For SRE, there's also:
- Be able to dive deeply into tech.
- Identify what the sacred cow systems are and keep them healthy and up.
- Deal with security issues.
- Deal with server issues (esp. overnight).
- Deal with zombie coworkers after overnights
- Deal with monitoring, observability, etc.
- Deal with comments from the rest of the organization.
- Be a calm presence in disasters like when the data center blows up.
- Align the OKRs into work.
- Deal with unplanned work (unexpected incidents, emergency upgrades, expired licenses, on-call work, outages, etc.)... and post-mortems for action items to remediate.
- Be on call like your engineers.
The harshest feedback he ever got was "Look, you're a great manager, and your team is good at what they do... but you run a boys club." People didn't want to deal with them because of their behaviors... So what did he do about it?
- Get rid of superhero mentality.
- Don't treat the title/role as "important."
- Talked to underrepresented groups to understand why they sucked.
- Looked at how they hired.
Takeaway: Diversity of skills is great, but diversity of people and cultures gets better diversity of ideas and approaches and the team itself gets better. Will they trust you-the-manager to help with their career?
"Diversity is a number, inclusion is a choice." DEI is fundamental to success and trust.
That leads to performance management... which should not be semiannual. Have weekly or biweekly one-on-ones. Know how you're assessed and align your work to the business' needs.
Your success is based on the success of your team.
To sum up:
- Learn from failure.
- Understand how work is done.
- Get really really organized (goal: Inbox Zero).
- Ruthlessly guard your calendar.
- Read, learn, and adapt. There's always a better way.
Do you want to be remembered for what you did... or how you did it?
Exploring Disconnects between Reliability Practitioners and Management/Executives
[Direct slides link | Direct video link]
Kurt Andersen and Leo Vasiliou provided the "author's intent" for why they wrote — and why they suggest you read — the latest "The SRE Report" (https://bit.ly/2023-sre-report). In this session, they'll hear about the logic, emotion, and controversy during survey writing and results interpretation. In summer 2022, an industry survey was run with 559 responses. The initial report on the findings was released in November 2022. Based on the self-identified organizational level by the respondents (e.g., Individual Contributor through Executive), they found quite a few of the inquiry topics had differing perspectives in their answer set. They highlighted these differences and provided some suggestions for bridging the perception gaps through the use of real-world situations. They took a naked look at some of the most surprising data and explored some of the open-ended questions where survey respondents could type in anything they wanted (and they did!).
I didn't take a lot of notes here (and a lot of the talk felt over-rehearsed). They walked through bits of the report (especially how responders' roles affect their answer to the Google-vs-Microsoft question) and did some role playing. Open ended questions often get a better response. Talking the language (tech vs business) of your audience is also often more likely to get the results you want (e.g., stress business value or risk).
Dealer's choice: What didn't make it into the report?
- (Leo) Size of "tool sprawl" problem (which is only a problem for ~2.1% of the respondents):
- IC — 57% not at all or minor, 43% moderate or serious
- Executive — 78% not at all or minor, 22% moderate or serious
- (Kurt) How are SREs organized; where do you report?
- 21.8% not recognized as SREs
- 23.6% Executive
- 20.4% Localized
- 17.9% Multiple
- 16.3% Within Development
To summarize:
- In order to achieve these results or solve these problems...
- We need the ability(ies) to...
- Success metrics look like this...
- They will be powered by this (these) tool(s)...
(The tool comes last; the problem comes first.) "Capabilities or abilities are the gateway between your speeds and fees on the business end and the tools and tech on the engineering end."
Note: If you're interested in being part of the pilot group, visit https://bit.ly/23-pilot.
Why This Stuff Is Hard
[Direct slides link | Direct video link]
After today's lunch break (soup, salads, short ribs, grilled sea bass, asparagus and portobello mushrooms, and creamy polenta) I continued with Lorin Hochstein's "Why This Stuff Is Hard." We all face challenges in doing the work of keeping our systems up and running, from ever-growing complexity to the time pressure of delivering new features into production. This talk brought these challenges into focus, treating them as first-class entities that are common to our work rather than being pathologies that are unique to our own local organizations. They also explored what we can do to increase our chances of success by recognizing the nature of these constraints.
Adaptive Universe
David Woods' assumptions:
- Resources are finite:
- There's never enough time.
- There's never enough people (headcount).
- The law of stretched systems: Even with more time and more people, any system will be given more and more work until it meets its capacity. This means it's really difficult to build up capacity (time or people).
- Production pressure means having to deliver on features without breaking anything
- Hard to find time to reflect.
- More time is spent planning versus reviewing/reflecting.
- Change never stops:
- Keep the system up despite changes.
- Code freezes — limit deployment because the cost of an outage varies with the time of that outage.
- "On a hunch, I decided to look at..." (like SSL cert expiration around 4pm PDT which is 12am GMT).
- "What changed?" In this example, time was the change: Not making a change can have its own risks.
System has boundaries; what's inside (the stuff we can control) is the system and what isn't (the stuff we can't control) is the environment.
We are all of us (except for one lucky person starting from scratch) prisoners of history.
The inevitability of complexity
We eliminate failure modes by adding complexity. The nature of our work to increase robustness is also increasing complexity.
We're in the control systems business. Dr. W. Ross Ashby's Law of Requisite Variety: "Only variety can destroy variety." Better control means a more complex model.
But what about reducing accidental complexity? We could... but we have finite resources (like time and people). We can make changes after incidents because the org sees the validity of doing that.
The local nature of perspective
We can only see part of the system. Consequently our understanding is always partial. We can't see the interactions by looking at the components. ("Dark debt" refers to the phenomenon where hidden interactions that you don't know are there can cause a change in component A to make component B affect component C.)
We have local rationality: Rational decisions based on what we know locally... which may affect the global environment.
"Something somebody didn't know" is often identified in a retrospective. Getting the information into the heads of the people who need it is essential... and grows exponentially hardware with the organization as it grows.
"The moment an action is performed, it ceases to exist." — Dr. Karl Weick, Sensemaking in Organizations. Work is thus invisible and ephemeral. It's hard to watch experts in action.
Communication and coordination
Distributed systems are hard (human edition). Incident response is a team sport, especially since we all have only partial views of the system. That team sport requires coordination. And effective communication is a difficult problem. It's even worse in a remote or hybrid world.
"Anyway, we're dead in the water until this figures itself out." In this case, "figures itself out" was the standby unit coming back up because the work to fail services over earlier was invisible.
(For more, see Dr. Laura Maguire's talk later today.)
So, now what?
- We can't escape the adaptive universe.
- We can't reduce complexity in the long run.
- We can't step outside our own local perspective.
- We can't do it alone and coordination is hard.
We can't eliminate those constraints but we can do better working within them. That means treating skills as first class.
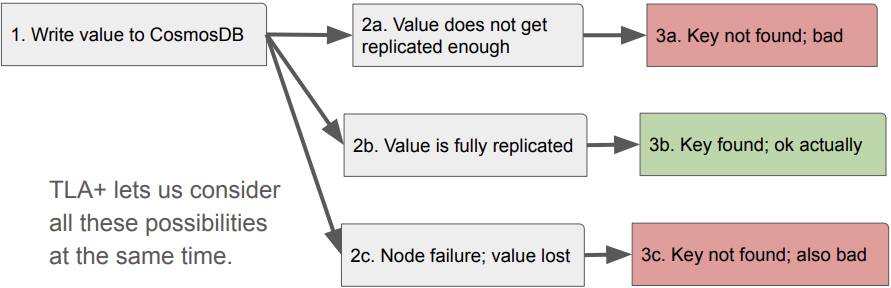
Turning an Incident Report into a Design Issue with TLA+
[Direct slides link | Direct video link]
A. Finn Hackett's and Markus Kuppe's talk discussed their experience using modeling-driven techniques as part of a postmortem deep dive into a long-lasting, high-impact outage at Microsoft. They built a precise specification of the micro-service architecture, most notably its foundational distributed database service CosmosDB. Modeling allowed them to go beyond the standard postmortem analysis and accurately determine the outage's root cause. The key to their approach was using TLA+, a formal specification language that let us concisely and formally describe the database's user-visible behavior under concurrency. By building a specification, they could thoroughly understand the underlying design issue and find bugs in the database's documentation. Through this case study, they demonstrated the value of modeling-driven techniques in postmortem analysis and illustrated how they can help avoid similar issues in the future. They also explained how we can use TLA+ to build precise and reusable specifications.
Story time: An incident. A performance optimization is deployed. Error metrics didn't noticeably change, but somewhere an uncommon client request pattern starts to fail very often. Lots of debugging later, the client considers Azure might be wrong. Azure devs investigated and they see the system is running too fast, latency is too broken, and roll it back. So what's the big deal? The client isn't seeing the errors (but it took 28 days to find), and we know why we rolled back... but the design-level insight is missing. What about the design made a component being too fast a problem?
Step 1. Understand the underlying system(s). CosmosDB is a planet-scale key-value store, a big distributed system, that uses consensus to figure out what to do. At a high level, the dispatcher wrote metadata to CosmosDB then queued a task to a worker. The worker asked CosmosDB for the metadata... which it couldn't deliver because of a race condition or caching or latency within the black box of CosmosDB based on its consistency and consensus settings.
Step 2. Represent the underlying system(s). Make a tiny facsimile of the thing in a model, simplifying and abstracting. While doing this, their approximations include the following:
- Ignore the detailed client API and just look at the plain key/value read/write.
- Server management can be ignored and they could focus on the client's view of the servers without knowing or caring about which.
- Ignore things the client can't see, just look at things the client can see (especially the weird stuff).
- Have a domain expert be the one to model it, ideally.
They built the model (reusable and complete) but it took 3 months to build with developers' input and took one day to use to generate the docs in this post mortem.
Demo time! (See the slides for details. There's a BOF tonight with the language tutorial if you care about it.)
Thinking in states (branching possibilities) can be problematic. This modeling "thinks" of all the stories:
Lessons learned:
- Problem is using session consistency without sharing tokens.
- Original mitigation changed the probability of the issue, but wasn't a fix. The issue was always there, just very rare.
- Clear when presented this way, but the issue was hidden behind APIs.
- Engineers were not surprised by our results; we confirmed what was suspected but could not be demonstrated.
- Modeling helped us think and investigate.
Avoiding Cachepocalypse in the Land of the Monolith
[Direct slides link | Direct video link]
After the afternoon break (chocolate covered strawberries, cherry-almond smoothie shooters, funnel cake fries, and churros with raspberry sauce and whipped cream) I went to the talk "Avoiding Cachepocalypse in the Land of the Monolith" by David Amin from Duolingo. Like many companies who switched to a microservice architecture, Duolingo runs a legacy Python-based monolith that is both business critical and not entirely owned by any one team. This monolith hit a scaling limit by exhausting memcached connections, but strangely only on a single node of the cluster. What followed was a debugging journey that spanned Python and C, took down production (specifically, the Spanish language) for an hour (because the deployment to staging mangled a cache that was shared with production), and required binary arithmetic to solve. The talk suggested strategies for mitigating unclear ownership of legacy systems, creating a fast and safe feedback loop for debugging in difficult circumstances, and coordinating a multi-team response to issues that threaten business continuity.
Factors in their eventual success:
- Make space to volunteer.
- Take calculated risks.
- Invest in fast, safe debugging.
Q: Non-sequitur: as someone who works at duolingo.. how good has your language-of-choice gotten?
A: Embarrassingly bad.
Q: Moving forward, do y'all now have ways to think about / test data format changes due to library upgrades?
A: We don't have a good mechanism other than an isolated test cluster.
Q: Can you talk more about how you made space to volunteer? What did that look like in practice at duolingo?
A: Having managers in the loop and explaining why so they wouldn't object.
Q: It's great to hear details of an incident from a consumer-focused company. Did you have to cut much red tape to share today?
A: No; they were very open about being open.
Q: Did you think about setting up some other piece of infrastructure like mcrouter as an alternate solution?
A: They talked about new-to-them options and didn't want to bring in new technologies and worry.
Q: Have you taken steps to avoid unintentional resource sharing between environments in the future and if so what are they?
A: Not yet. We're dealing with this right now.
Q: What are some of the lessons you've learned about introducing microservices in a monolithic environment? Is the goal to get rid of the monolith longer term?
A: You can't stop caring about it until it's actually gone. You need handoffs as people roll off of maintaining it. The team owning the monolith is trying to decompose it (whether it goes away or becomes less important).
Q: How did you go about identifying that connection count would be a tipping point for your system?
A: They actually hit the limit a couple of times.
Q: Can you say a little more about how those library versions became skewed between stage and prod?
A: They were trying everything, including the upgrade in staging... but didn't roll it back, which is why production broke (oops). They want to have better insights into the deployed library versions.
Q: Any chance you could convince them to make the Match Madness lessons a little less aggravating?
A: Let's talk specifics after and will forward them later.
Q: Would you consider setting up separate VPCs or even subnets with env. specific security group rules?
A: Yes; that's a great idea.
Incident Archaeology: Extracting Value from Paperwork and Narratives
[Direct slides link | Direct video link]
Next in the session was Spotify's Clint Byrum talking about "Incident Archaeology: Extracting Value from Paperwork and Narratives." Why do we fill out incident reports? Why can't we just get to the fixes and move on? We'll discuss how we learn from the aggregate of incidents at Spotify and turn this pile of paperwork into a gold mine of insight into how we work and operate our systems.
Clint was here to promote psychological safety, share their process, and inspire and collaborate with us. Note that companies default to not sharing, and it takes effort to make sharing the norm.
We're looking at breadth ("across all icebergs") not depth ("get to the bottom of one iceberg").
Incidents are not just paperwork. The value of the process is communication (during a stressful event), accountability (even in a blameless culture; it's more to help them learn expectations than to blame them), coordination, and if you're lucky, learning. But what are we asking people to do? A lot: Write the detailed timeline, write the report, update the status, file the tickets, facilitate discussions, document actions, estimate impacts, track remediations....
They started digging. If you have the concept of an incident then you have artfacts. But people often forget. They were looking for answers. They made some hypotheses. First, "After-hours or on-call will have high MTTR and complexity." Falsifiable, built on the shaky ground of MTTR, and even shakier ground of measuring complexity. They looked at a year's worth of incidents... but almost no incidents happen at night. MTTR in the aggregate showed no patterns. Measuring complexity was contentious and ultimately fruitless. But this is when they found out nobody likes paperwork and about 45% of the time there weren't post-mortems or retrospectives.
Bring in data scientists earlier in the process to get better analysis.
Hypothesis: "A year later, postmortems are the norm." It's either "exist or doesn't"... but they only moved from 55% to 62% of having post mortems. Some happened without documentation. They needed to come up with easier processes, simpler documents, and so on, to make it easier to right. They also leaned more into their curiosity to find out how much incidents were affecting productivity.
People will bug you if they got bugged. Lower-impact incidents with limited spread had fewer post mortems.
How do you do this?
- Go find artifacts.
- Decide how much time you can commit to studying them.
- Hypothesize about it.
- Make a methodology that will fit in the time box.
- Run it by a data scientist.
- Break up the artifacts into a list and study each one.
- Analyze the data.
- Write it up, learn, share (widely!), and rejoice!
Note: Determining correlations is really problematic:
- Your sample size is really small.
- Your population is often unknown.
- Sane p-values are hard to come by.
- More of a census.
Other findings:
- Nobody can define the start or end of an incident (terms undefined). The default is "start when ticket opened, end when ticket closed," and 75% never changed that.
- Uptime success can hide massive problems with productivity.
- 80% of incidents are declared during business hours.
- Only 30% of declared incidents are local change failures.
An Organizational Response to Incidents: Designing for Smooth Coordination in High Tempo, Large Scale Software Incident Response
[Direct slides link | Direct video link]
The final talk of the session was Jeli's Laura Maguire on "An Organizational Response to Incidents: Designing for Smooth Coordination in High Tempo, Large Scale Software Incident Response," which Lorin Hochstein mentioned in his "Why This Stuff Is Hard" talk above. She thought the title was boring and even she wouldn't come to this talk, so she retitled it: "Followship: A Proposed Model of Incident Organisation for How to Have Better Incidents: A Cognitive Systems Approach to Coordination."
In the Incident Command System (ICS) framework, the Incident Commander role has long attracted organizational attention for selection, training, and competency identification. But, the majority of participants in an incident response are "followers" who carry out the direction of the commanders. So, making the incident responder group better overall is a force multiplier. This talk drew from primary research to explore the role of the follower and the characteristics of good "followship." It also looked at the organizational preconditions that aid in incident response-both the everyday work of incident response and in large-scale software outages. This talk was most relevant to leaders and followers who carry a pager and, more generally, to teams looking to improve communication, coordination, and collaboration both internally amongst members and externally across organizational boundaries. Attendees left this session with new ideas of how to structure their incident management functions, along with practical tactics and strategies for use in their next outage.
We've long been fascinated with leaders who can share vision. The central thesis: What constitutes good following over good leadership. Followship is the adaptive choreography of experienced responders working together for a common goal or purpose.
As cognitive demands rise, the ability to coordinate decreases. The paradox of coordination is that in complex adaptive systems, everyone's model is going to be partial and incomplete. Therefore we need multiple diverse perspectives to handle non-routine or exceptional events. But there's additional cognitive load working with others, so investments and strategies are needed to keep the cost of coordination (CoC) low.
Several strategies often used include delay, delegate, drop, and diminish, all of which are counterproductive for a resolution. Having one person (the incident commander) doing all the work makes them a de facto bottleneck, slowing down the incident response. We also see freelancing, people taking initiative, making their own changes that the coordinator may not know of, and leads to side-channeling.
Cognition has several elements:
- Perceiving (what you look at/for, sense, seek cues for, receive cues for, or recognize)
- Reasoning (memory, recall, application of knowledge; diagnosing, troubleshooting, forming (and validating or not) hypotheses, inferring, judging, planning, correcting, and modifying)
- Attending (focusing the attention, prioritizing, switching contexts, or ignoring)
- Acting (the tasks to reduce time responding to incidents; recruiting, updating, signaling, synchronizing, grounding, initiating, delegating, accepting, and adjusting)
Practice exercise in recognizing cognitive work: What did you do during the early days of the pandemic? Learn, bake, cook, knit, plant, paint, new puppy, fermentation... and learn how to fly (parasailing: the ultimate social distancing).
Cognitive work is asking and answering:
- What is happening?
- Why is it happening?
- What's next?
- How quickly?
- What do I need to do now? Later?
- What are the consequences?
- What are our goals and priorities? And which can I sacrifice?
- Who has the skills and knowledge to help me?
- What do they need to know about the current situation to be useful in helping resolve the outage?
- What tasks should I give to whom?
- How long will it take for them to be done?
- What work might be deferred as a result?
- What does that mean for my users? How/when should I let them know?
SRE work is asking and answering the same questions.
We need to lower the overall CoC, share that, be intentional about when and how to push those costs onto other people or across organizational boundaries.
Followship is:
- Anticipating the sequencing of work needed to be accomplished and of others' needs.
- Initiating work, communications, or outreach.
- Signaling intent to others to aid coordination.
- Proactively providing information and updates, and stating the assumptions you have about the event.
- Relaxing goals and constraints to show reciprocity. Put aside your goals or priorities to help another team, assuming they'd help you later too.
- Synchronizing activities.
- Preparing themselves to be useful.
- Looking in and listening in.
Common ground, mutual knowledge, beliefs, and assumptions about the problem, is essential for good followship. Also, good reciprocity is essential.
Anti-patterns:
- Shame, blame, retrain
- MTTI (innocence)
- Pushing the costs of coordination across boundaries
To get better:
- Observe — Ask the following questions:
- How do people interact with one another?
- Do they seem to share similar beliefs and assumptions about how the system works?
- If not, do they notice? Do they question it and share knowledge?
- Do questions go unanswered?
- Are people comfortable or are they stressed out?
- Is disagreement okay? For everyone or just some responders?
- Do people support one another?
- Talk — Develop shared language for "talking about how you talk:"
- Common ground
- Signaling
- Updating
- Anticipating
- Synchronizing
- Prioritizing (and re-prioritizing!)
- Grounding
- Analyze — Post-incident analysis helps with cognitive work and reveals:
- How the system fails
- How the system behaves under different conditions
- How the system interacts
- The degree of observability into different parts of the system
- What dependencies exist and to what extent do they impact performance
- What knowledge was needed to diagnose or repair the problem
- How flexibly that knowledge can be applied to novel problems
- How easy (or difficult) it is to get help from others when needed
After the day's sessions ended I headed to the convention center for the conference reception. They were sneaky keeping the appetizer lines near the entry — cheese, chips, crudites, dips, spring rolls, potstickers (both vegetarian and chicken but they were mislabeled), and chicken satay — and not necessarily telling people the desserts were in the middle of the room and the mains — sweet and sour chicken, stir-fried tofu and veggies, beef bulgogi, white and brown rice, and tuna poke — were at the far side of the room. I ate enough to have a decent dinner (and even skipped dessert).
After the reception I bailed on the lightning talks and on slideshow karaoke in favor of going up to the room and getting off my feet for a bit. I'd let a local ex-LISA friend know we were in town and he swung by the hotel for drinks and schmoozing in the bar for about two hours. (I had a Maker's Mark, neat; it was less expensive than I was expecting it to be.) It was great to catch up. He left around 10:15pm and I was in bed by 10:30pm or so.
I woke up after about eight hours of still-poor sleep. It was late enough in the morning that I started with a shower, took my daily COVID test (negative yet again), did a quick skim through the work email, and generally got ready before heading down to the lobby for breakfast (same as yesterday but without the potatoes and bacon) and then to the attached convention center for the third and last day.
Human Observability of Incident Response
[Direct slides link | Direct video link]
My first talk of the day was "Human Observability of Incident Response" by Matt Davis from FORM.com. In learning from incidents we also learn from each other, and about each other. The choreography of coordinating our response requires us to understand one another at the same level we're attempting to understand the incident, interconnected as a unified socio-technical system. This talk gave practical advice on producing repeatably better outcomes by revealing the Human in Incident Response.
We started with a joint musical activity: We listened to a musical piece and made sound together with our voices for about a minute. We intended to work together, outlined our basic contract, tuned to each other interdependently, and stayed committed to a common goal. Choreography was group-directed by coordination via signals, voices starting, raising, lowering, and stopping. Attention is the center of the mandala, the attention we're giving to a response, and what we're focused on. All around the rest of the mandala is the awareness (AKA adaptive choreography). We're working in the realm of attention and awareness. During an incident you need problem solvers (local awareness and decisions), who may need to check in with a communicator or communications lead (who coordinates with the stakeholders), and they're conducted by the incident commander (who has a full view of what's going on).
Incidents, in musical terms, are effectively improvisations. Something has happened (such as dark debt raising its head), and we don't have time to plan (rehearse), so we have to make it up on the fly (improvise). If we act like a band while performing should we also act like a band outside of incidents (at rehearsal, at regular operations)? That makes it become second nature, muscle memory kicks in, and coordination costs are lower.
"Improvisation has no existence outside of its practice." — Derek Bailey
Complex contexts require improvisations. In extreme environments (like arctic responders) it is impossible to plan everything. Being capable of improvising must be the focus in complex contexts. Collaboration is essential.
As we work towards remediation, we are committed to participate in common grounding, which is a process of communicating, testing, updating, tailoring, and repairing mutual understanding and mental models.
What do signals look like? Skilled (musical) improvisers draw upon and adapt highly resilient motifs during performance.
Mental models in music corresponds to those in software:
Technology stack Musical stack Networks Keys Languages Scales Process Chords Data Rhythms Tools Instrument Quality harmony Runbooks Melody Codebase Structure Parlance Style Similarly, signals can correspond as well:
Technology stack Physical stack Group emails Touch Closed loops Breathing Video calls Eye contact Threads Tone of voice Memes Body carriage DMs Placement in room @-mentions Vocal direction Emoji/Reacji Movement Doc Comments Smell Complication (a rubik's cube puzzle) vs complexity (can solve it in under two minutes, with muscle memory).
When conducting incidents, what questions can we ask:
Supporting humans means we need to:
- Where in the response trio do I belong (conductor, problem solver, communicator)?
- Do we have common communication?
- What routines can we handle as a group?
- Do we know where to find expertise among our ranks? (And what, who, and where is it?)
- How are we each perceiving production pressure?
- Is anyone fatigued? Who hasn't eaten?
- What are the competing priorities (like feature work)?
- What time of day is it?
- Listen. Ask others their perspective.
- Update. Give new joins a status. Check in often.
- Guide. Suggest alternatives. Guide others through their decisions.
- Monitor. Questions around confusion, split attention, lack of response, problem solvers missing check ins, how people are interacting (psych safety).
- Repair. Ask clarifying questions, pull participants together for a no-work status meeting, get replacements so people can take breaks.
Reciprocity tactics include:
- Create resources that help situational awareness, e.g. a service-to-team matrix, RSS feed channels for vendor outages.
- Include diverse perspectives. Informed decisions are better than rapid ones. "The world needs all kinds of minds."
- Break tunnel vision by asking questions; What do we hope the outcome will be if we do this? Are there other outcomes?
- Be a "rubber duck" for others to get ideas flourishing.
- Develop adaptive capacity through collaborative training.
"Human practitioners are the adaptable element of complex systems" (Richard Cook).
Q: The outcomes of the Practice of Practice sessions seem predictable in one sense and unpredictable in another. How have you communicated the value of that unpredictability to management, and how did they take it?
A: Ensure management and leadership were invited. Made sure that the 80-minute company-supported weekly event was available to all, and a summary (in storytelling format) provided and put in the wiki to inform everyone later.
Far from the Shallows: The Value of Deeper Incident Analysis
[Direct slides link | Direct video link]
Next up I went to "Far from the Shallows: The Value of Deeper Incident Analysis" by Verica's Courtney Nash. We began in the shallow end, where the waves were calm and the familiar sand warmed our toes: Can Duration tell us anything about our incidents? We tested the waters and felt we could linger here a while, but it's somehow... unsatisfying. We waded a bit deeper, gaining comfort and confidence. Could other things tell us more — severity perhaps? No, it floated away, providing no guidance.
Shallow data or subjects:
- Duration — Your data are skewed which renders averages meaningless. (Histogram of incidents over time, left-skewed.) It can't tell you what you want to see.
- MTTR — Won't tell you anything about reliability, effectiveness, if you're getting better, how better or worse the next one might be, how bad one might be. Move on from this unreliable metric.
- Severity — Negotiable. It's a variable proxy for customer impact, effort required to fix, and urgency. It may be automated or updated, and is subjectively assigned. It can be gamed. It's not a useful metric.
Note that severity and duration are not correlated.- Root cause — Simplifies causality in complex systems but fails to identify upstream or other systemic factors and it over-indexes on human decisions and actions.
We drifted out with the tide and our toes barely skimmed the bottom — we began to tread water. Looking out farther, we realized the water became murky, the details hard to discern. There was a distinct draw to dive down, where we uncovered a whole universe we didn't realize existed. Coordinated schools of vibrantly-colored fish darted by, weaving through intricate mazes of plants and coral, and in the darkest depths lurked surprising and unexpected dangers.
Like Walt Whitman, incident stories contain multitudes. They contain rich sociotechnical detail compared to linear accounts that are focused only on technical elements. They convey multiple, different perspectives, reveal themes and patterns, and zoom in and out to paint a picture of the whole system.
Stories are a powerful way of getting the right knowledge into the right people's heads. We all read each others' stories. In being transparent and sharing the knowledge we're inspiring others to do the same.
You may have qualitative metrics (feelings) that you can't measure quantitatively. These are depths and details you only get when you dive deeper.
Going through the retrospective process you may notice things that aren't necessarily causal but which may be helpful later.
It's here, in the deep end of incidents, that yields the most value if we're willing to dive in. In this talk, she showed how the shallow data of incidents reveal little, and gave examples of incident reports from the VOID (Verica Open Incident Database) that illustrated the value of substantive, qualitative investigation. She examined how this hard work benefits others, our collective messages in bottles feeding back into a safer and more navigable sea for everyone.
What are the acceptable performance, economic failure, and unacceptable workload boundaries? Your operating point needs to be within the three of them. Digging deeper lets you get a better understanding of the boundaries and identify where your adaptive capacity may be.
What about near misses (which aren't in the VOID)? They reveal gaps in current knowledge, communication breakdowns, pockets of expertise, misaligned mental models, cultural and political forces, and the range of assumptions that practitioners have about their system.
You need to stand back and let the people you've trained (to expand the pockets of knowledge) solve the problem instead of jumping in and just doing it yourself.
"We realized that this was a failure mode that didn't line up with our mental model of how the job system breaks down. This institutional memory is a cultural and historical force, shaping the way we view problems and their solutions." — Ray Ashman (Mailchimp)
Building a community is hard work: We're building a community of practice around this, shining a light on the importance of this work, and supporting, educating, and caring for each other. "A rising tide lifts all boats," as they say.
thevoid.community is the database but it's also a refuge.
Q: Executives and large organizations prefer metrics over stories because they often don't have (or take) the time to understand the incident stories. How can we find a balance between those needs and instincts, and the value provided by more holistic analysis? Any summary metrics that you'd recommend over MTTR to communicate broadly?
A: Yes! If you get the report, there's an entire section talking through the sociotechnical metrics (and they're in Clint's talk).
Q: How do you move your org out of the shallows?
A: If you make people feel seen and valued, they're more likely to [want to] participate. IBM's office of the CIO (OCIO) has run an initiative within OCIO and is getting hundreds of exec-level people reviewing incident reports regularly.
Q: Now that we've seen the depth that exists, how do we do our first dive? (Presuming that we don't need to reach the depths in one go.)
A: Pick a non-high profile, not scary, not politically fraught incident, collect all the artifacts, talk to the people, be an information archaeologist. The "Howie Guide" from Jeli is a good start. Use that to build the narrative as if you're a journalist. But don't pick the big scary high-profile one first.
Q: Are we able to contribute to the VOID anonymously if we can't get sign off from our company?
A: Yes; talk to Courtney offline.
The Revolution Will Not Be Terraformed: SRE and the Anarchist Style
[Direct slides link | Direct video link]
After the morning break I attended a three-talk block. The first was Austin Parker's "The Revolution Will Not Be Terraformed: SRE and the Anarchist Style." Site Reliability Engineering is more than a job title, discipline, or functional role-it's an organizational and cultural force advocating for change. How did this come to be, and how can practitioners become more effective in driving a culture of reliability in their organization? In this talk, he discussed the past, present, and future of SRE through the lens of movements such as Agile and DevOps and how they have been co-opted and commoditized. Their analysis not only included technical and organizational themes, but connected them to social studies and the organization of peoples. Takeaways included an appreciation for how SRE can become a more effective motivating factor for not only reliability of systems, but of the people that underpin them.
Fun fact: Human tongue prints are unique. ("You didn't say the fun fact had to be about me. Malicious compliance is the best kind.")
Like many other sociotechnical movements, SRE is a reaction to the commodification of other sociotechnical movements, like Agile, DevOps, and (now) SRE.
- Agile — The manifesto was written in the early 2000s. Many places now sell solutions not software and are less worried about needing Agile. "If Kubernetes went away tomorrow we'd be upset, but if Excel did the world would be toast." It's a mushy, cultural amorphous thing, intended for bottom-up deployment. Over time it was commodified.
- DevOps — This was the late 00s. The intent was to break down silos... and a lot of the literature is from an IT or executive point of view. Now, DevOps is a product sold by a number of cloud providers.
- SRE — We're back to mushy and cultural, synthesizing the mushy cultural parts of Agile and the automation and technical bits of DevOps. The people doing the work and responsible for the systems should have a say in their priorities. "If it worked for Google it should work for us." (Audience response: "It didn't work for Google." Laughter.)
So finding commonalities: What about the anarchist political tradition: Mutual aid. It is the conscience of human solidarity, the unconscious recognition of the close dependency of everyone's happiness upon the happiness of all. We're all interdependent. One ant is nothing but they work as colonies. Other species are similar in providing mutual aid. That leads to mutual confidence in individual initiative. That's true historically for humans, too, but that's not recorded as much by historians because who reports the good stuff? SRE's job is to build mutual confidence and thus support individual initiative.
Social ecology is based on the conviction that nearly all of our present ecological problems originate in deep-seated social problems.... In effect, the way human beings deal with each other as social beings is crucial to addressing the ecological crisis. The point social ecology emphasizes is not that moral and spiritual persuasion and renewal are meaningless or unnecessary; they are necessary and can be educational. But modern capitalism is structurally amoral and hence impervious to most critiques. Power will always belong to the elite and commanding strata if it is not institutionalized in face-to-face democracies, among people who are fully empowered as social beings to make decisions in new communal assemblies.
SREs build citizens not workers. SREs are organizers, not heroes. SREs create confidence through education. SRE supports initiative through structures. SREs should not centralize power but to distribute it. The more people have direct control of their environment and what they do leads to better results.
Don't take his word for it. Read the cited works (not only things from O'Reilly). Do some liberal arts.
Q: Do you have any advice for those of us who feel exploited and may be laid off?
A: Unfortunately, as a manager he can't comment because he's constrained by the National Labor Relations Act (NLRA). That said, look to Google and organized labor.
Implementing SRE in a Regulated Environment
[Direct slides link | Direct video link]
Next I attended the "Implementing SRE in a Regulated Environment" talk by Sandeep Hooda and Fabian Tay of DBS Bank. SRE is an approach that many organizations find attractive and ideal. In particular, for organizations bound by regulatory obligations regarding the use of technology in service delivery, there are valuable insights to be gained to better safeguard organizations from operational and financial risks. In this talk, they shared how they successfully enable SRE Practices of conducting Root Cause Analysis, Chaos Testing, and Trend Analysis in line with the regulatory expectations. In the region, they were one of the pioneers in the financial industry to adopt SRE.
DBS is the largest bank in SE Asia, headquartered in Singapore and often voted the world's best bank. Regulators regulate the banking industry so compliance with the rules is essential. The high level of regulation is intended to provide resiliency, reliability, accountability, observability... all of the SRE tenets. So what are some myths and facts?
Myth 1: There's only a single root cause to every disruption. They perform "no single root cause analysis," since seeing one root cause blinds you to other causes and contributing factors. They use the vision tree and through blameless culture they focus on the system where the failure occurred instead of who is at fault, and see those inevitable failures as learning opportunities to improve on the system's shortcomings. They have C-suite support for this.
Myth 2: Do not break what is not broken. Most of the time, a lot of us default to this line of thought. You can't manage the unknown unknowns. Agile and more rapid changes have some risk. But what's the difference between "working well" and "not broken"? It's not what will break; everything will. It's more when will it break? Chaos testing is the new norm: It increases the test effectiveness and coverage, leads to more-stable and -reliable systems, and provides more insight into the unknown unknowns. (Their tool? "Wreckoon," with a raccoon plushie as the mascot holding a mallet labeled "Chaos." Reach out if you want to know more about their tools.)
Myth 3: Data-driven insights uncover the bigger picture and trend analysis. They believe that with data we can obtain valuable insights to make better decisions. Using the SRE principles they perform blameless incident retrospectives to identify where the fault lies. By seeing things from different perspectives, they are able to analyze trends, patterns, and behaviors.
To sum up, it's hard but not impossible to do it. They're making progress. The regulating body has realized this is the right approach, and that there's no single root cause but multiple contributing factors. This is a competitive advantage for the bank.
Financial Resiliency Engineering: Taming Cloud Costs
[Direct slides link | Direct video link]
My last morning session talk was Shopify's Darren Worrall on "Financial Resiliency Engineering: Taming Cloud Costs." Systems Engineers (or SREs/Engineers) have always deeply cared about resource efficiency. There is no better time to apply your skills to the cloud than now! This talk dived deep into the work Shopify undertook in 2022 to significantly reduce our cloud infra footprint and costs, detailing the tools, approaches, and trade-offs they had to navigate along the way.
SRE gets involved a lot with the non-functioning requirements like availability, sustainability, performance, security, and efficiency. They're a Ruby shop, with MySQL, Redis, and several other applications each with their own up- and down-stream dependencies. They run mostly on Kubernetes on Google Cloud.
The cloud is a flexible utility so the graph of costs often looks like a sawtooth with peaks and valleys.
Story time: Their leadership says they need to cut costs, to get more value out of the cloud. They set an ambitious and meaningful target (in dollars), and quickly prioritized how to get there. Risk: Cutting too deep or in the wrong place can cause outages or break SLOs. Make a spreadsheet tracking (among other things) team, effort size (like S, M, L, XL), and estimated monthly savings ($ to $$$$). Pick the best options and go do the things. It was chaotic (intentionally).
Time goes by. S and M work finishes up but the impact on spend isn't happening as expected (even discounting the incomplete L and XL work). They dug deeper and found teams were lacking the context for estimating the savings. Can they provide tools to give that context so the cost savings estimates were better?
Yes; they used flame graphs. (Digression with examples.) They applied their tools to the billing and service data and it worked really well. (The in-talk example was made up.) They can also use pprof views to show where the costs were actually adding up. They then crowdsourced the spreadsheet to get revised savings estimates, and defined what would be in the next sprint. It was much more successful.
Focus on what matters:
- Get incremental wins in the largest systems.
- Eliminate underutilized clusters (low-hanging fruit)... but be careful of intentionally underused infrastructure reserved (e.g.) for resiliency.
Some of their wins:
- Bin packing (packing Kubernetes pods onto Kubernetes nodes). They improved their bin packing. By using GKE cluster autoscaler set to Optimize-Utilization, reducing unallocated resources (e.g., those on a node not requested by a workload), and rightsizing resource requests.
- Vertical pod autoscaler (VPA). It monitors the current and past resource consumption and based on that recommends values for the containers' CPU and memory requests. It checks which of the managed pods have the correct resources set and (if not) kills them so they can be recreated with the update requests. It sets the correct resource requests on new pods.
They scrape those values and load them into their monitoring system as well.- Cargo culting. Practice included copy-pasting bits of Terraform. They were using SSDs when not needed, buckets with inappropriate or missing lifecycle policies, and more expensive machine types. They had to set guardrails (which could be overridden by any engineer), using Atlantis, with onftest to check the lifecycle policies.
So how did they get from their bad place to "good"? They can't keep working in a "drop everything" mode. What does "good" even look like? "No surprises," meaning expectations are set in advance as to what things should be: Demand management, capacity planning, and consumption insights (including anomaly detection). Part of this is being able to join workloads, owners (with contact information), utilization, and billing data. Tracking all that is problematic and they wound up moving back to spreadsheets. They're making the inventory more robust (self-descriptive with identifying nodes, pods, buckets,tier, cost owner, team, and COGS/OPEX). Having self-describing resources greatly simplifies the ability to report centrally without double-keying or joining different sources of truth. Different implementations should use the same schema.
Unit costs: Infrastructure costs to sustain 1M RPM. Can they set expectations, SLI, or SLO for this? Can they connect costs with values?
Lowering costs is not the goal. You can always turn everything off and delete the data to bring costs to zero. Maximizing value is closer to the goal, though that may not be precise enough.
The talk ran long and there was no Q&A session.
How To Take Prometheus Planet Scale: Massively Large Scale Metrics Installations
[Direct slides link | Direct video link]
After lunch (soup, salad, and pan-seared chicken or salmon) I switched to Track 2 for Vijay Samuel's and Nick Pordash's "How To Take Prometheus Planet Scale: Massively Large Scale Metrics Installations." Observability at eBay had been on an exponential growth curve. What was a low 2M/sec ingest rate of time series in 2017 had grown to roughly 40M/sec with active time series close to 3 billion. Their current cortex inspired architecture of Prometheus builds sharding and clustering on top of the Prometheus TSDB. It is relatively simple to shard/replicate tenants of data in centralized clusters. However, large clusters with growing cardinality become less useful as query latencies degrade considerably. In 2020, Google published a paper on its time series database Monarch which is dubbed as a planet scale TSDB. The paper gave us some useful hints on how we could potentially decentralize our installation and go fully planet scale.
What started off as a humble prototype to federate queries to TSDBs deployed in Sydney, Amsterdam and the US from a centralized query instance, had become a living breathing entity that allows us to deploy their TSDBs anywhere in the world using simple Kubernetes operators, GitOps and intelligence on top of the Prometheus TSDB.
This talk focused on:
- The development of field hint indices to fingerprint time series and use the same for pointed query fanout
- Functional query push down on top of Prometheus storage
- The struggles of managing a planet scale deployment and using Gitops to mitigate pains
- Other lessons learned
Observability at eBay: Instrument with common open source libraries, onboard through the custom cloud console, harvest events and logs through the observability platform, alert based on thresholds or anomaly detection, or visualize through the sherlock.io console.
What's their scale? 1.25M Prometheus endpoints scraped, ingesting 41M per second, with 2B active time series, fulfilling 8000 queries per second, retaining raw metrics for a year.
Around 2018 they started. Prometheus (an open-source CNCF-backed time series database) was becoming more and more popular. Challenges adopting it: They didn't support HTTP Push (it's since been added), it was complicated to provide a federated view, and scaling was hard (you could scale vertically by throwing CPU and memory or horizontally by manually sharding).
Goals:
- Keep it simple, use fanout writes and not solve replication, do deduplication at query time, and use the TSDB as-is.
- Simple tenanting, routing namespaces to dedicated cluster of Prometheus TSDBs
- Integrate tightly with Kubernetes, discovering shards using the Kube API Server with abn Operator to manage the clusters.
- Support PromQL and Gradana.
- Alerting and recording had to be supported.
- Support twice the cardinality limits of the legacy platform.
Pass 1, centralized approach. There were still challenges: Not being able to keep up with new use cases (onboarding), hard to support high cardinality, too many dependencies monitored, etc. Pass 2, they incrementally improved by introducing aggregators. Those drop labels before series hit storage, raw labels aren't always necessary, and a high cost to store raw series. That saved 60% CPU and 80% memory as compared to using recording rules to drop cardinality.
Google unveiled Monarch, a planetary-sized TSDB. At eBay they had an internal hack week and they looked at replicating it there. At the end of the hack week they had at least a proof of concept working. However, they had some challenges: They don't have the same awesome tech that Google has (ideally substituting with open source technology), used GitOps for spec management, and they were basing their work off the white paper that didn't talk about all of the aspects.
How could they scale storing the data better? Move storage closer to the source. The deployed per region/availability zone/Kubernetes cluster. Number of tiers are composable based on scale requirements. The tradeoff is that rollups get bubbled up: The lead stores raw data, the zone has rolled up data for the region, and the root has higher-level rollups (user queries). Queries are defederated. Field Hint Indices provide knowledge on where a series might reside, allowing them to scatter queries to only matched targets. The user is oblivious to the data layout. Delivery through GitOps to manage the specs of leaves, zones, and root on Git, and had control loops watching over Git to deliver the changes into the cluster.
What did they get out of this?
- Better scaling capabilities for high cardinality
- Better ingest/query performance
- Independently usable metric stores (esp. in the leaves and zones).
- Horizontal scaling based on zone/leaf installation allows for fixed shard sizing
Lessons learned include:
- Independently usable metric stores make things easier.
- GitOps made life easy: Specs can't be lost.
- Internal APIs aren't a bad thing.
- Continuous observation and evolution is key.
What's next?
- Automatic rollups
- Support native histograms
- Open source it... maybe? Chat with the speakers after!
[A lot of this was straightforward, and I was sleepy since it was immediately after lunch, and I didn't take a lot of detailed notes. -ed]
Your Infrastructure Needs To D.I.E.
[Direct slides link | Direct video link]
The last invited talk of the conference was "Your Infrastructure Needs To D.I.E." by DigitalOcean's Timothy Mamo. What can a diamond heist that occurred in 2003 teach us about InfoSec's CIA triad? Well, that the old way of doing security will not help us as we try to move towards being more Cloud Native. Simple tools and a lot of ingenuity can easily allow an attacker to ruin your day. So how can we make use of cloud native ways of development whilst also ensuring security?
We need infrastructure that can D.I.E.
Designing infrastructure that is Distributed, Immutable, and Ephemeral automatically integrates security by default by increasing the bar for attackers. Further, adding controlled chaos to the process ensures that you are continually learning and improving, increasing confidence in the ability to troubleshoot. In this talk he highlighted how the D.I.E. triad can help us be more secure while expecting for things to fail, and embrace the chaos.
We're going on a diamond heist!
Based on a true story: 2003, Antwerp Belgium, gang of six people: Genius (specializes in alarm systems), monster (electrician and lockpicker), king of keys (can replicate any key), diamond dealer (insider), speedy (fidgety one and friend with the mastermind), and the mastermind (Bartolo, charming and suave Italian man). Target is a vault two floors down from the diamond center with 250 safety deposit boxes.
Challenges: 3-ton vault door, keypad to disarm sensors (including seismic, IR heat, magnetic, lights, security cameras, etc.). If any alarms trips the on-site security team rushes down to the vault.
The CIA triad is Confidentiality, Integrity, and Availability.
Bartolo disguises himself as a diamond merchant and ingratiates himself with the security team and gains their trust. He's allowed to place pinhole cameras in and outside of the vault, and to spray the sensors with hairspray to disable them. The heist is planned for the weekend when security is offsite. They cover security cameras with black plastic bags and the sensors with styrofoam, and enter from the building next door's garden. They have a duplicate key to get into the vault (but it's not needed because Bartolo notes the security team left the key to the vault in the unlocked utility room next door to it. They get in, smash open the deposit boxes, and stuff their bags full of loot... which is worth approximately EUR 100,000,000.
You can't outfox a fox. Attackers and hackers are persistent and want into your system. Vulnerabilities are never-ending.
How do we tackle the problem? We're still in a heist mindset for our infrastructure security. We need to move to more of a cloud native mindset, using the tools and ideas that the cloud allows us to. One of those is ensuring our infrastructure complies with the Distributed, Immutable, and Ephemeral (DIE) triad.
The D.I.E. Triad
New paradigm to support recovery and resilience.
- Distributed infrastructure is by definition not having all your eggs in one basket. Spread across multiple providers, zones, regions, etc., makes it fault-tolerant and highly available. For example, CDNs have made DDOS attacks a thing of the past (in the DIE world anyhow). If you're affected, you can turn off the component and still have your application up and running on other infrastructure.
- Immutable means the individual infrastructure components are unchanging once it's deployed. If nothing is changing there's nothing writing to disk and there's no state, so you don't need to ssh into the system or kubectl your pod. That makes it a lot harder for an attacker to get in. If it's immutable and a change happens, you know you've been attacked (and lost), and you can redeploy or revert. Upgrades are "Create new image, deploy new image, route traffic over, and destroy old image." Miss something? Create new image, deploy new image, route traffic over, and destroy old image. (Kubernetes does a lot of this for your pods; we need to do the same for servers and clusters.)
"Implement the bamboozle layer." — Kelly Shortridge.
"And who doesn't like messing with attackers?" — Timothy Mamo.
- Ephemeral means the individual infrastructure components (including passwords; use something like HashiCorp Vault!) are short lived or temporary, fulfilling its purpose then dying.
Applications should be stateless so attackers can't get information like passwords and tokens.
With DIE you can ignore CIA: If I'm distributed then don't need to worry about availability. If I'm immutable then I don't need to worry about integrity. And if I'm ephemeral then I don't need to worry about confidentiality.
He did a demo. It's all automated by Terraform and Packer.
Sprinkle some chaos
We want to sow some chaos! Implementing chaos engineering shows us what we may need to improve on the system. For example, if the database password is static not ephemeral we know we should change to the latter. You need observability, monitoring, and alerting for chaos engineering to work.
We really want to experiment. Start off with a hypothesis (such as "I think my system will do X if Y happens"). That informs what you need to monitor, what redundancies you may need when things go awry. You can test the experiment to confirm or invalidate the hypothesis. That way you can identify which systems are pets and which are cattle.
Do I need to do all of this at once? No. Complex systems need more handholding than the simple examples we saw here. Learn about and understand your environment. If your system can't DIE because it's stateful, how can we make it more secure? Use decision trees (see Kelly's talk from Tuesday)!
In conclusion, the more your system is DIE the less your infrastructure impacts you and the more secure your infrastructure will be.
Plenary: Not All Minutes Are Equal: The Secret behind SLO Adoption Failure
[Direct slides link | Direct video link]
After the afternoon break (cookies!) I attended the penultimate plenary session, "Not All Minutes Are Equal: The Secret behind SLO Adoption Failure" by Capital One's Michael Goins and Troy Koss. They helped us understand, calculate, and eventually prove SLOs value. Despite SLOs frequent introductions across industry forums and literature, their actual formulaic definition is obscured. They showed how to look past the disconnect of marketing and the actual calculations of SLOs. They demonstrated the key differences between time-based vs event-based measurements. They compared and contrasted these methods while reviewing a real-world example of a high-severity incident. After establishing a common definition, they reviewed the many key signals that SLOs and error budgets offer: Slow burn, error budget recoveries, step function deviations, and so on. These signals let teams latch onto empirical evidence to better understand their system's health and discover unreliability. After all, you can't improve what you don't measure.
People think SREs only work on the stuff that nobody else wants to, but we really do that, plus reliability measurement, toil elimination, release engineering, event and incident response, observability and monitoring, continuous testing, and more.
- Start by looking at the industry publications.
SRE = SLO + error budget (AKA EB)
SLO + EB = Crazy
SRE = Crazy- Experiment with the metric: Is the error budget in Events or are events really in time? SLOs should correlate with what is currently known about system health. "Not all minutes (60-seconds) are equal."
- Fix what went wrong. SLI = Good / Total * 100 → 0% < SLO < 100% → [error budget]
- Understand the signals. What can we understand from the signals? We can see when a change was introduced, leading to a slow burn with recovery (in the error budget), and a later change, incident, and fast burn (burning down the error budget).
Error budget signals:
- Movement (slow burn, fast burn, recovery)
- Association (change, incident (incl. missing ones), bug, alert)
- Action (5Ws and H)
- Fanfare and action. Now that we have actions and monitoring and signals and all that, how can we bootstrap teams with default SLOs? What should the default SLO be (98.5, 99.5, 99.9, 55.5555, ...?)?
SLO(default) = ( bad / (( EB% - 1 ) * Total ) + 1 ) * 100
Given a target %EBR calculate an Objective.
Error budget policy:
- Who does what, when?
- Accountability
- Reinforcement (team member changes, re-orgs)
- Enhancements to the SLO (changes to SLI or objective)
(Note that we're helping them get started; they'll shift or change over time.)- Scale. Now that we have the right people in the room discovering the right indicators, how do we do it?
- Start: SLIs availability (5xx) and latency (sec) to provide a baseline.
- Inspect different layers (services, APIs, edge, client, to equip SLIs).
- Add edge cases: SLIs for (400, 408, 409, client-side javascript errors, retry logic, etc.).
- Map to customer interactions (authenticate/login, complete a transaction, etc.).
Define scope → Instrument → Assess baseline → Understand customer goal → Define EB policy (prod + dev + eng) => (Re)define scopeSee the appendix for the math formulas.
Plenary: Hell Is Other Platforms
[Direct slides link | Direct video link]
The final plenary session of the conference was Alex Hidalgo's and Andrew Clay Shafer's "Hell Is Other Platforms." Deliberately or inadvertently, everyone builds a platform to support their business mission. And in doing so we often look to what others have done to get us there. But: what if other's principles, practices and platforms aren't applicable to our context?
In Sartre's "No Exit" people are brought to a mysterious room in hell where they had all expected medieval torture devices to punish them for eternity, but eventually realize they had been put together to torture each other. Andrew Clay Shafer as DevOps and Alex Hidalgo as SRE both waited for Platform Engineering to join them in hell. During their suffering they will explain how you can best retain your agency, identify your needs, and understand how you can avoid the afterlife; while also outlining how we all got here in the first place.
"I like to celebrate the annual death of DevOps, 2019–2014 (15, 16, 17, ...)."
We talked a little about the history of DevOps: "You build it, you run it" (Amazon 2006) and then Allspaw's Dev + Ops @ Velocity 2009.
The five stages of SRE... and of Ops, DevOps, etc.:
- Denial
- Anger
- Bargaining
- Depression
- Acceptance
Systems gotta systems, be they operating, distributed, sociotechnical, etc. Someone's gotta administer them. System administration moves up the stack; we still have to manage them even though the abstractions are higher. Someone somewhere has to take actions to keep the systems running.
There will always be Ops. Anyone who says otherwise is in Sales, Marketing, or denial.
This was more of a humorous talk (with lots of meme slides, though not quite to the level of Mickens' 🏈🐺🌴🌴🌴) so I don't have a lot of useful notes.
Closing remarks
[No slides | No direct video link]
Concluding thoughts: How do you put a bow on this conference? Sarah asked what people are going to takeaway: How to fine tune Kafka, it's not always DNS, I'll have to rethink queuing, I'll look more into adaptive capacity, I need to learn more about management... but most often, she heard how supportive this community is, and how grateful we are to have been able to collaborate in person again.
Thank you to all of our sponsors, the program committee, the USENIX staff and board, all our volunteer speakers, and all of us. There are 683 people here from 18 countries and 196 different companies.
- SREcon23 APAC is in Singapore in June.
- SREcon23 EMEA is in Dublin in October.
- SREcon24 Americas is Mar 18-20 in San Francisco; CFP opens around August.
After the conference wrapped, I continued chatting with folks until they headed off to their evening plans. I went upstairs to start packing (so I'd have less to worry about in the morning) and finalize my own dinner plans: Taurinus Brazilian Steakhouse in downtown San Jose with a local friend of mine. Sadly his wife couldn't make it (she got stuck at work) and nobody from the conference crew was able to join us. I didn't track what we all ate — I know I had a caipirinha from the bar; asparagus, caprese salad, gouda, mango salad, parmagiano reggiano, prosciutto, salami, and smoked salmon from the salad bar; cheese puff, fried plantain, and fried polenta at the table; and bacon-wrapped chicken, beef rib, chicken leg, flank steak, leg of lamb, pork parmesan, pork rib, pork sausage, ribeye, and tri-tip all carved table-side.
I got back to the hotel around 9:15pm, finished my initial packing, and got everything ready for the morning before heading to bed.
Travel day! After another night of not only insufficient but also poor sleep, I skimmed through my email and social media, took my final COVID test (still negative yet again), drafted most of my expense report (which I wouldn't be able to submit until I had the hotel bill itemizations, the receipt for the Lyft to the airport, and the receipt from parking at DTW after my 10:19pm scheduled arrival), showered, finished packing everything except the laptop, and got dressed before heading down to the hotel breakfast buffet. I wound up getting scrambled eggs, breakfast potatoes, bacon, pork sausage, chicken sausage, a bagel with cream cheese and lox, a small chunk of brie, and fresh pineapple (and I ignored the pancakes, parfaits, other fruit, and other pastries). After breakfast I went back upstairs for my luggage, checked out of the hotel, and called for a Lyft to the airport.
I got to the airport without incident, left my cane behind at baggage drop (oops), realized it when I was about to go through the TSA scanner so had to get my stuff back, go downstairs for the cane, and come back upstairs for Take II. Cleared security without other incident and made it to my gate about 2.5 hours before boarding.
The first flight was mostly unremarkable, though it was turbulent thanks to the weather and it was on a regional jet so there was no IFE system. Once again our arrival gate was next to my departure gate, so after a brief walk and brief wait I got onto my second and last flight of the day. Its IFE worked!
We got into Detroit a few minutes early. After a brief walk, tram ride, and walk, I got to the baggage carousel and soon thereafter my bag was there. I grabbed my coat out of it and stuck my CPAP and laptop bags in it, reserving my keys and wallet, and headed to the terminal shuttle to get back to the parking deck and my car. Luckily it was right where I left it and I was on my way home.
I got home, turned up the thermostat, unpacked, and went to bed exhausted... and unable to sleep until about 1am EST (10pm PDT).